Models
Since the deep learning based KT models can be categorized into deep sequential models, memory augmented models, adversarial based models, graph based models and attention based models in our work, we mainly develop the DLKT models by these four categories in pyKT.
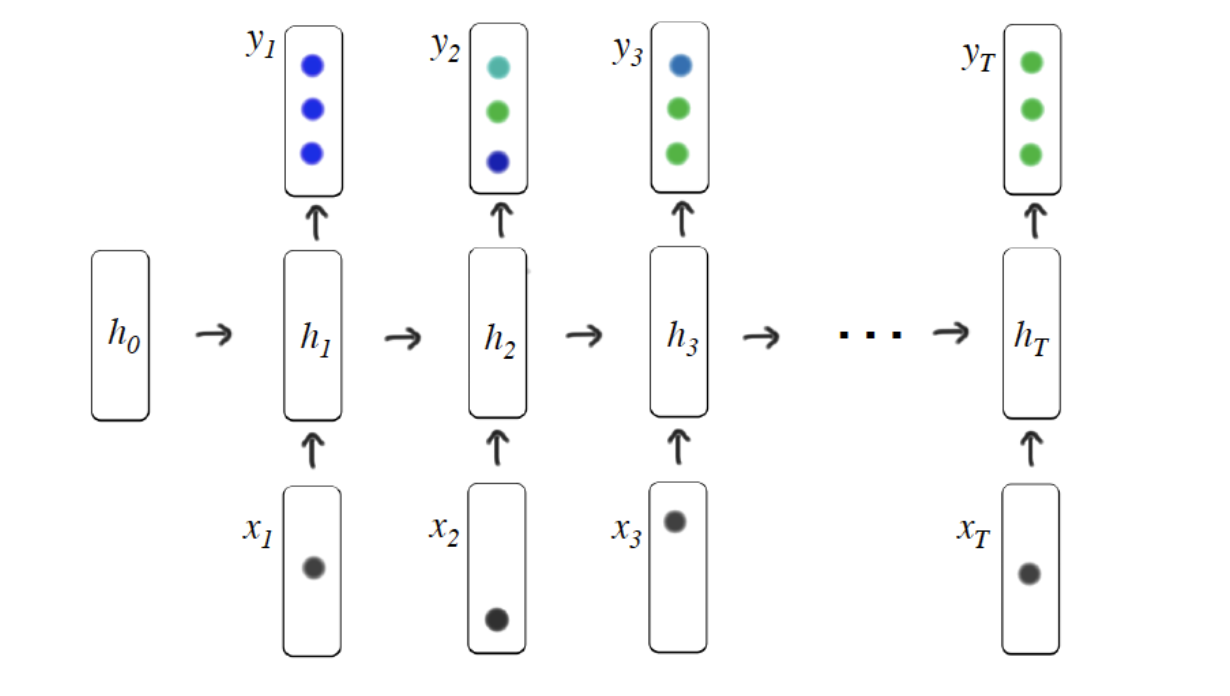
DKT
DKT is the first model that uses Recurrent Neural Networks (RNNs) to solve Knowledge Tracing.
DKT+
DKT+ introduces regularization terms that correspond to reconstruction and waviness to the loss function of the original DKT model to enhance the consistency in KT prediction.
DKT-Forget
DKT-Forget explores the deep knowledge tracing model by considering the
forgetting behavior via incorporate multiple forgetting information.
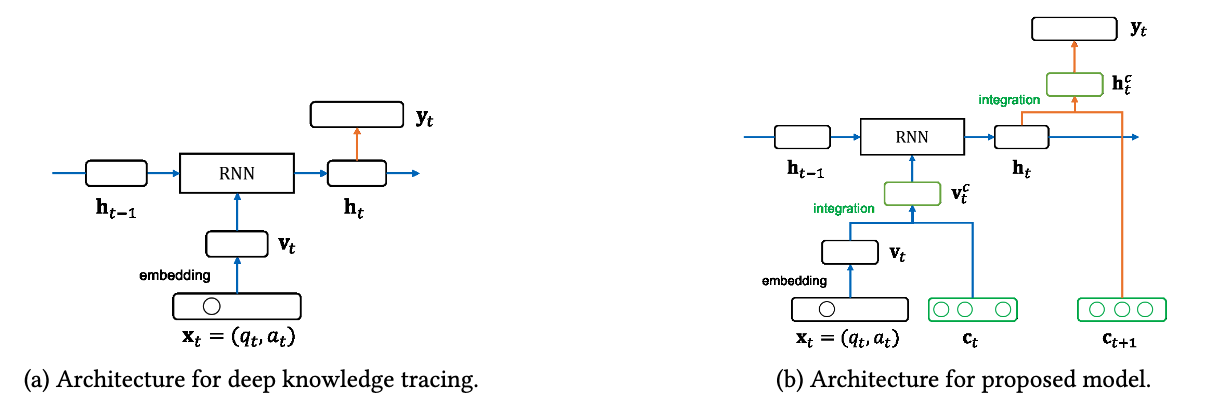
KQN
KQN uses neural networks to encode student learning activities into knowledge state and skill vectors, and calculate the relations between the interactions via dot product.
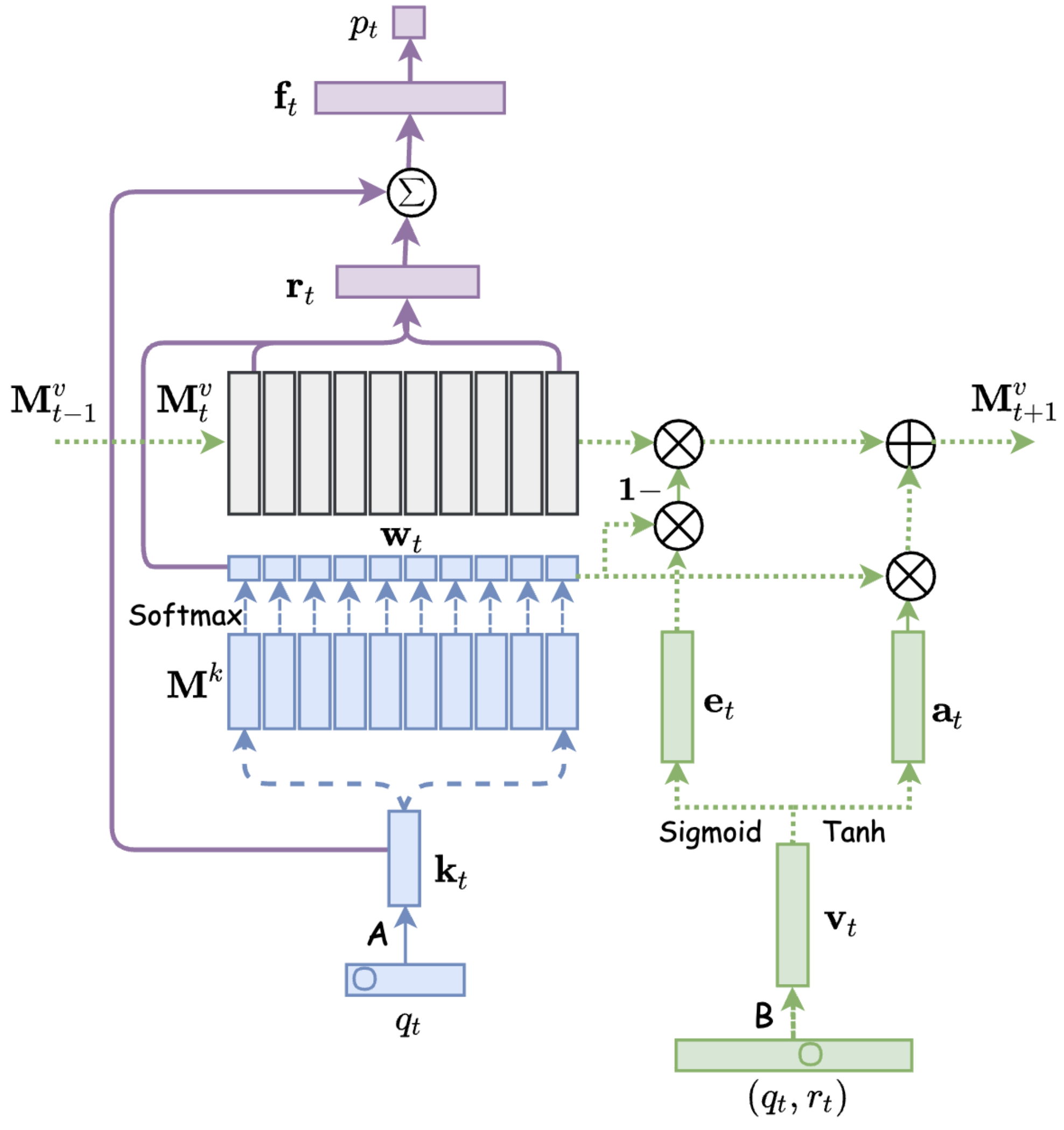
DKVMN
Dynamic key-value memory networks (DKVMN) exploit the relationships between latent KCs which are stored in a static memory matrix key and predict the knowledge mastery level of a student directly based on a dynamic memory matrix value.
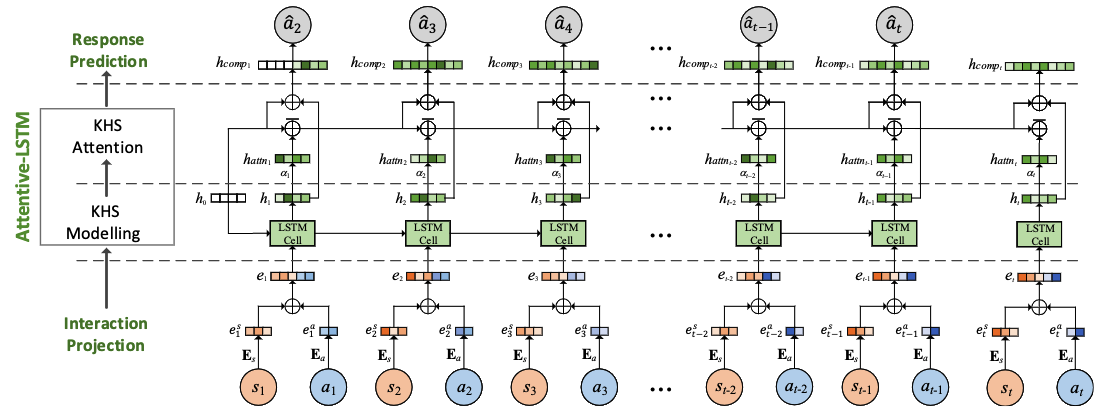
ATKT
Adversarial training (AT) based KT method (ATKT) is an attention based LSTM model which apply the adversarial perturbations into the original student interaction sequence to reduce the the risk of DLKT overfitting and limited generalization problem.
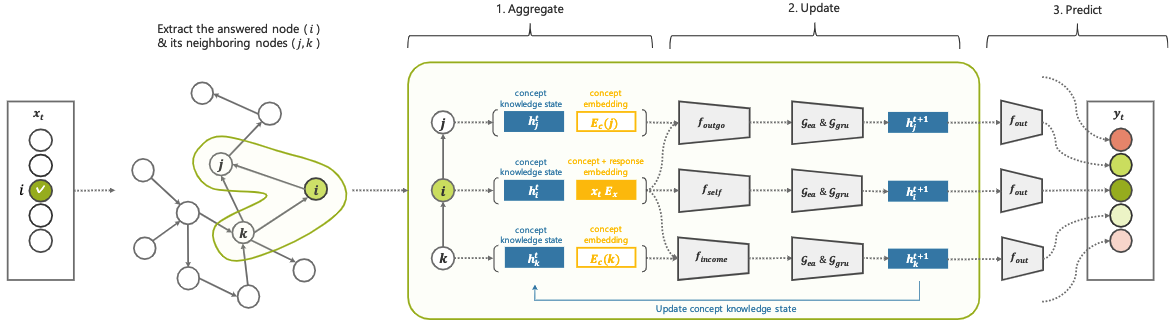
GKT
Graph-based Knowledge Tracing (GKT) is a GNN-based knowledge tracing method that use a graph to model the relations between knowledge concepts to reformulate the KT task as a time-series node-level classification problem.
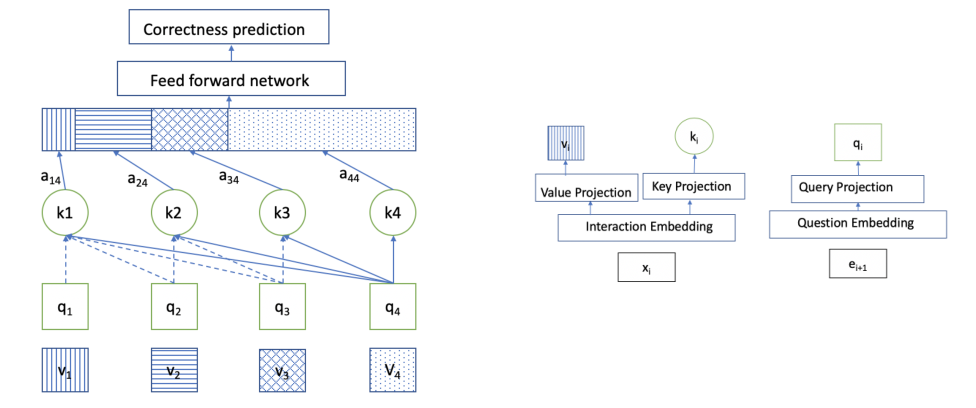
SAKT
Self Attentive Knowledge Tracing (SAKT) use self-attention network to capture the relevance between the KCs and the students’ historical interactions.
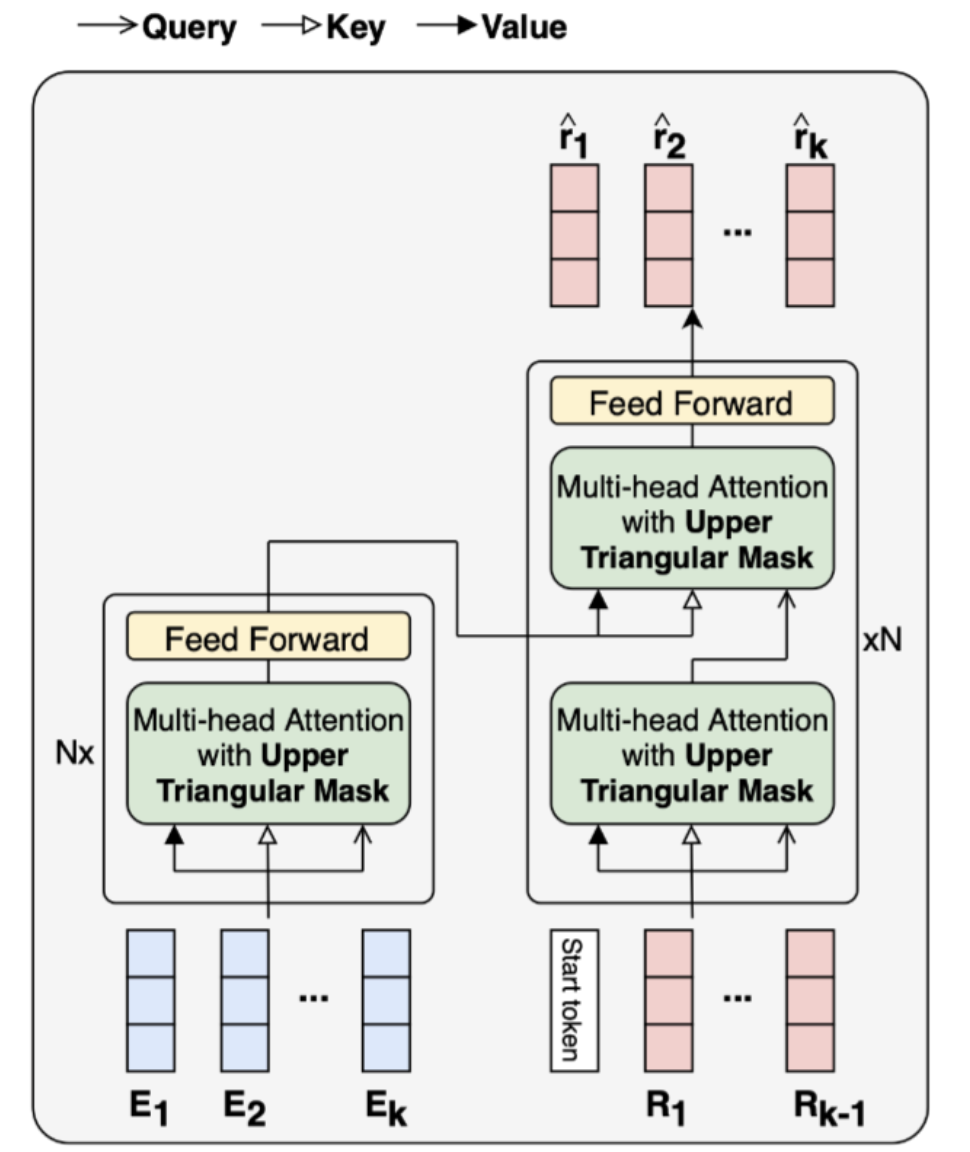
SAINT
Separated Self-AttentIve Neural Knowledge Tracing(SAINT) is a typical Transformer based structure which embeds the exercises in encoder and predict the responses in decoder.
AKT
- Attentive knowledge tracing (AKT) introduce a rasch model to
regularize the KC and question embeddings to discriminate the questions on the same KC, and modeling the exercise representations and the students’ historical interactdion embeddings via three self-attention based modules.
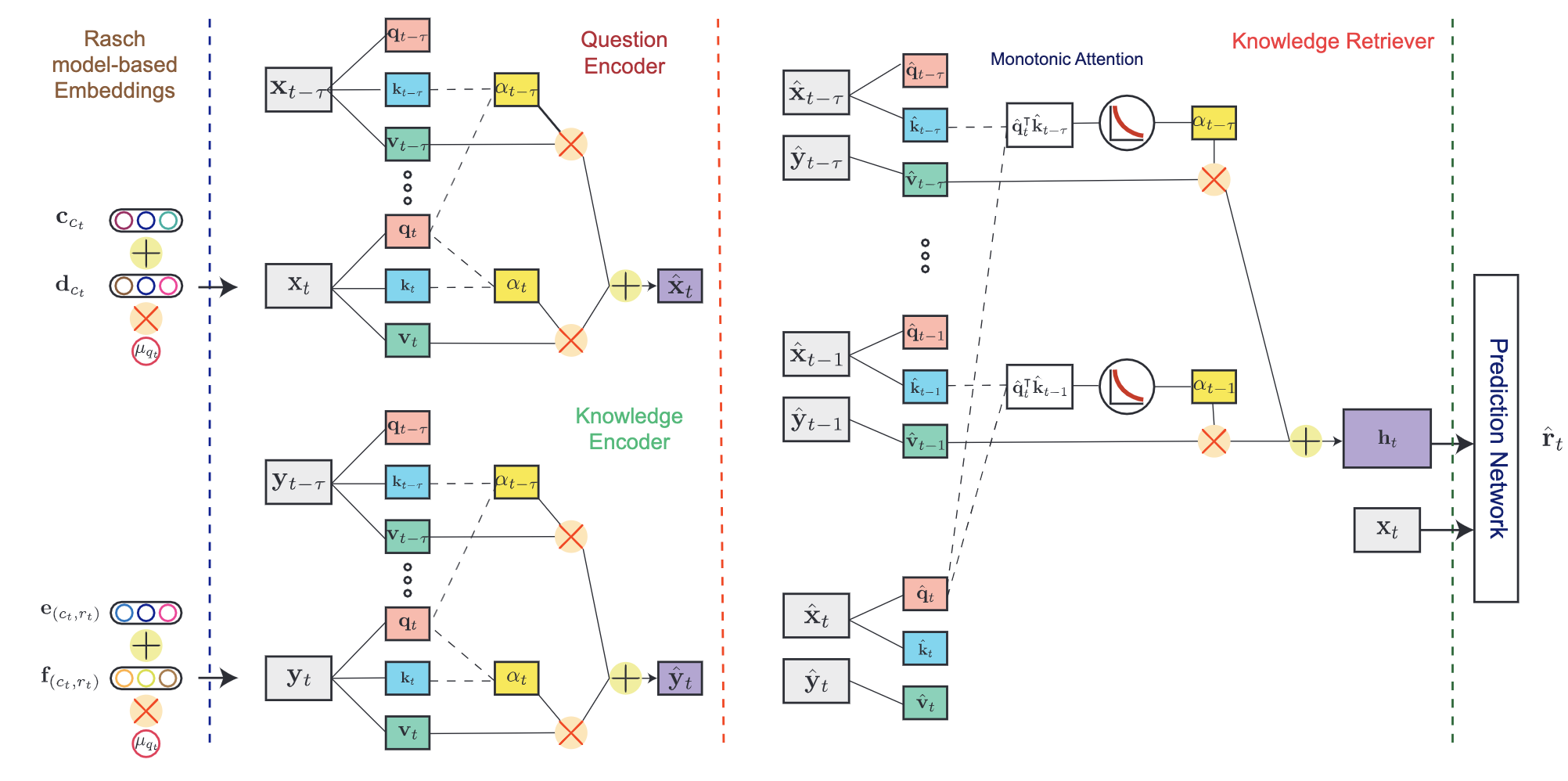
SKVMN
This model unifies the strengths of recurrent modeling capacity and the capability of memory networks to model the students’ learning precocesses.
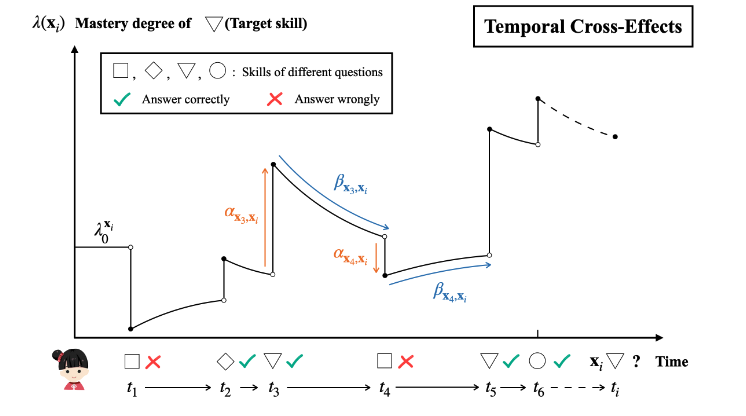
HawkesKT
HawkesKT is the first to introduce Hawkes process to model temporal cross effects in KT.
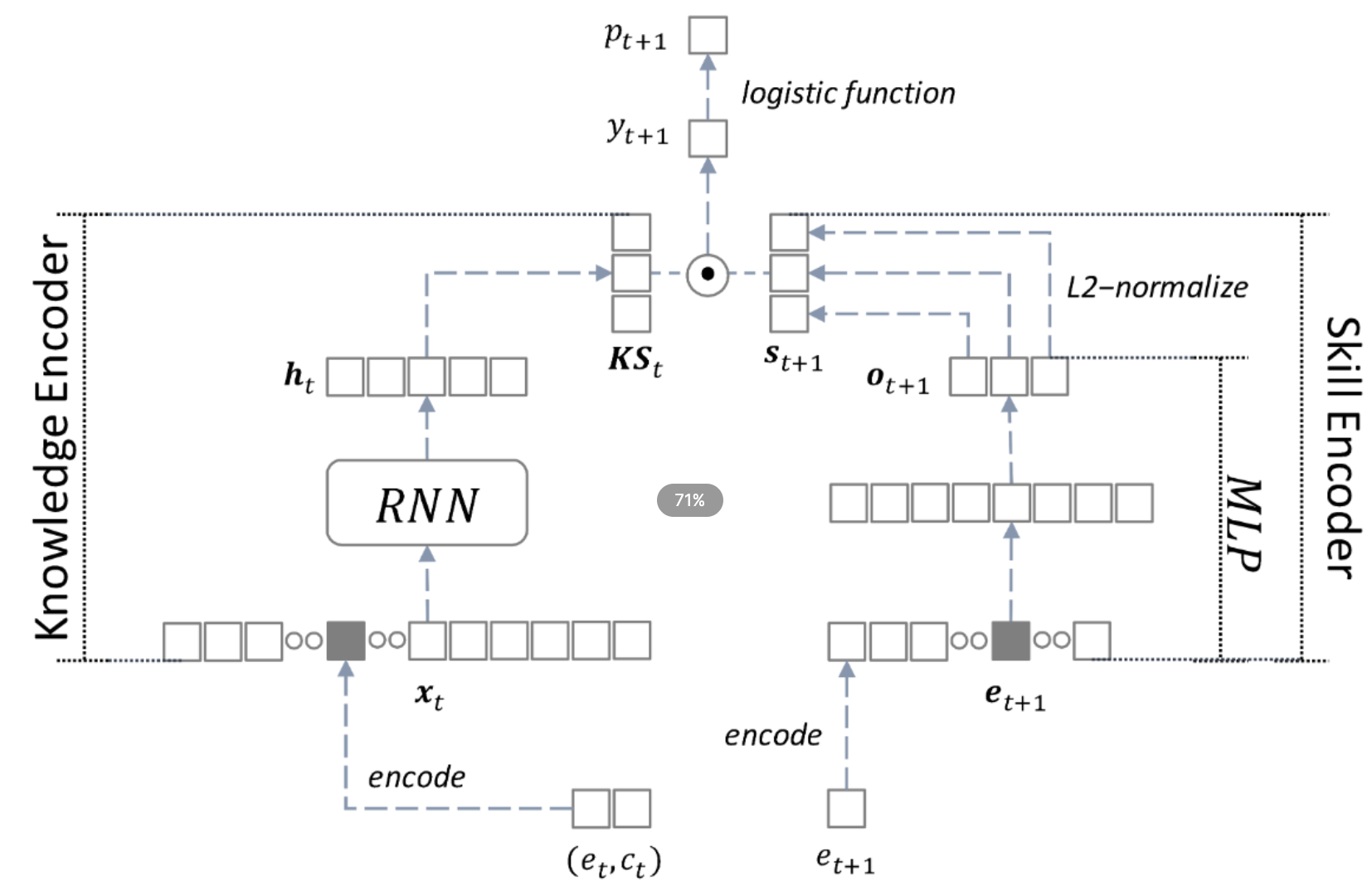
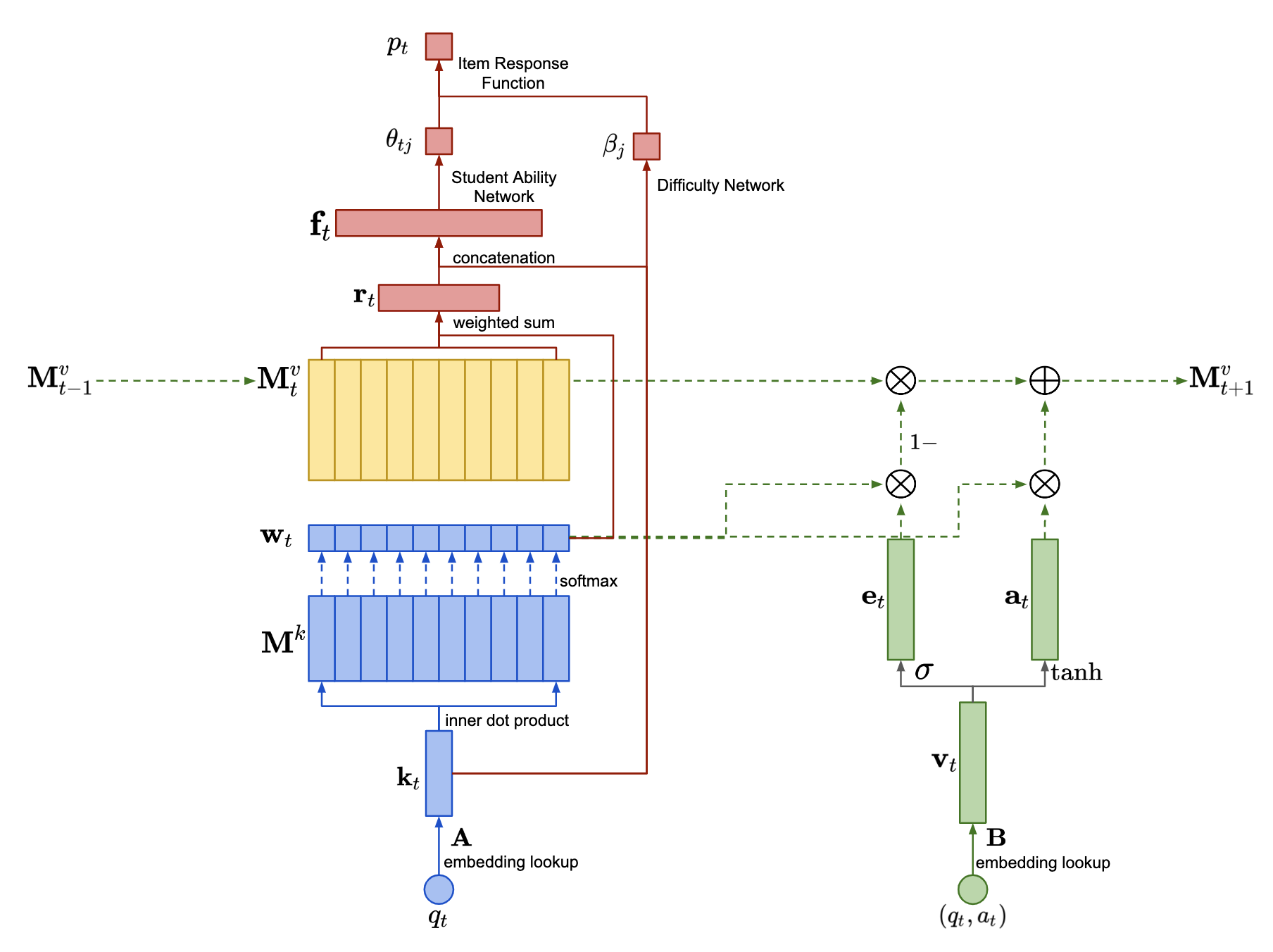
Deep-IRT
Deep-IRT is a synthesis of the item response theory (IRT) model and a knowledge tracing model that is based on the deep neural network architecture called dynamic key-value memory network (DKVMN) to make deep learning based knowledge tracing explainable.
LPKT
Learning Processconsistent Knowledge Tracing(LPKT) monitors students’ knowledge state by directly modeling their learning process.
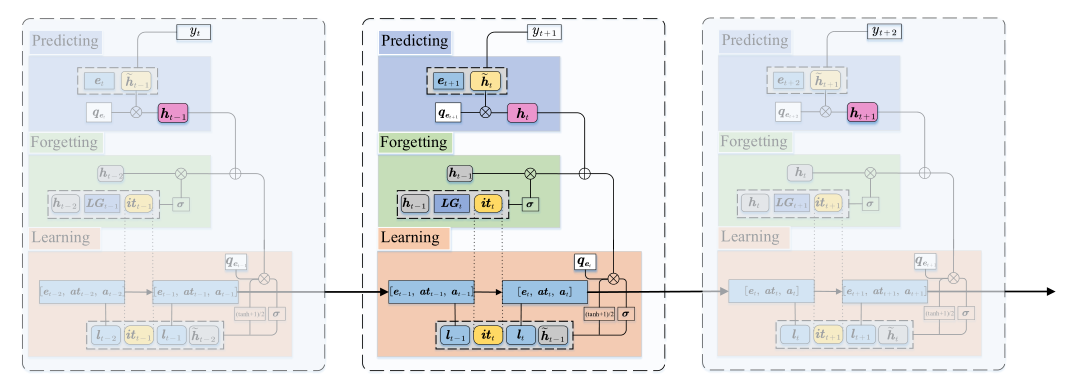
DIMKT
The DIfficulty Matching Knowledge Tracing (DIMKT) model explicitly incorporate the difficulty level into the question representation and establish the relation between students’ knowledge state and the question difficulty level during the practice process.
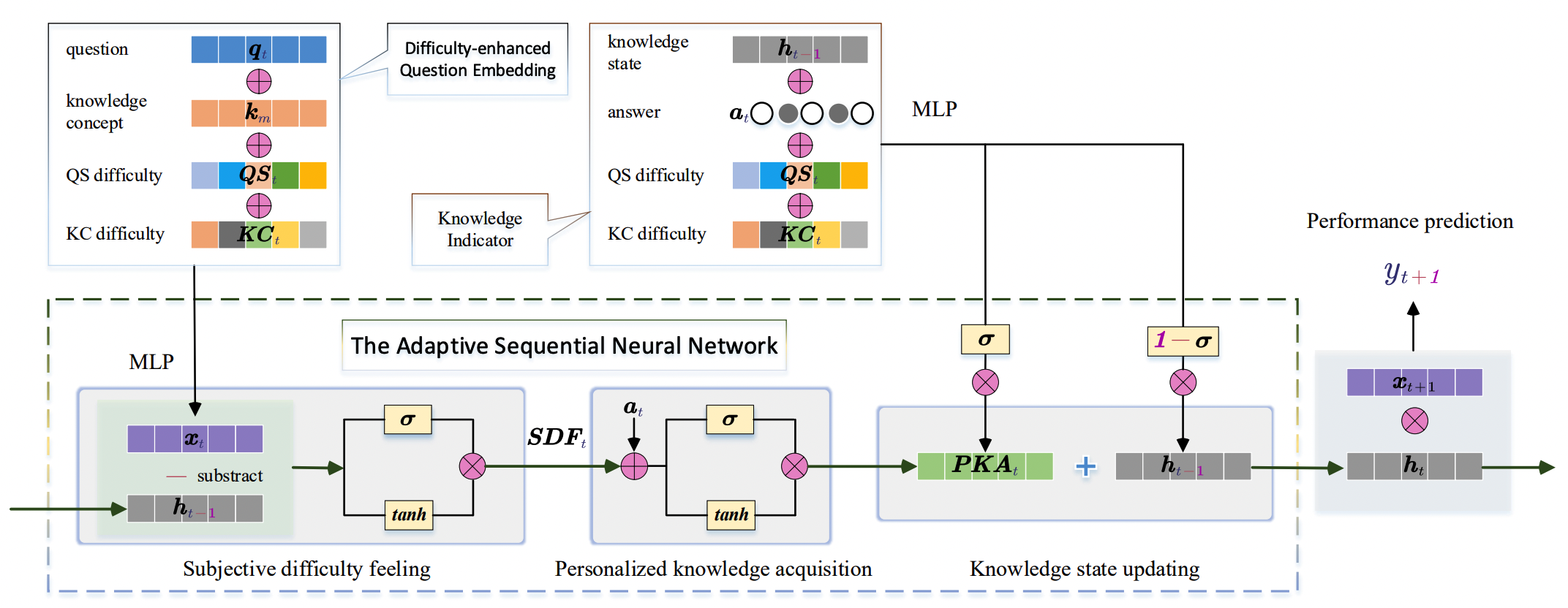
IEKT
Individual Estimation Knowledge Tracing (IEKT) estimates the students’ cognition of the question before response prediction and assesses their knowledge acquisition sensitivity on the questions before updating the knowledge state.
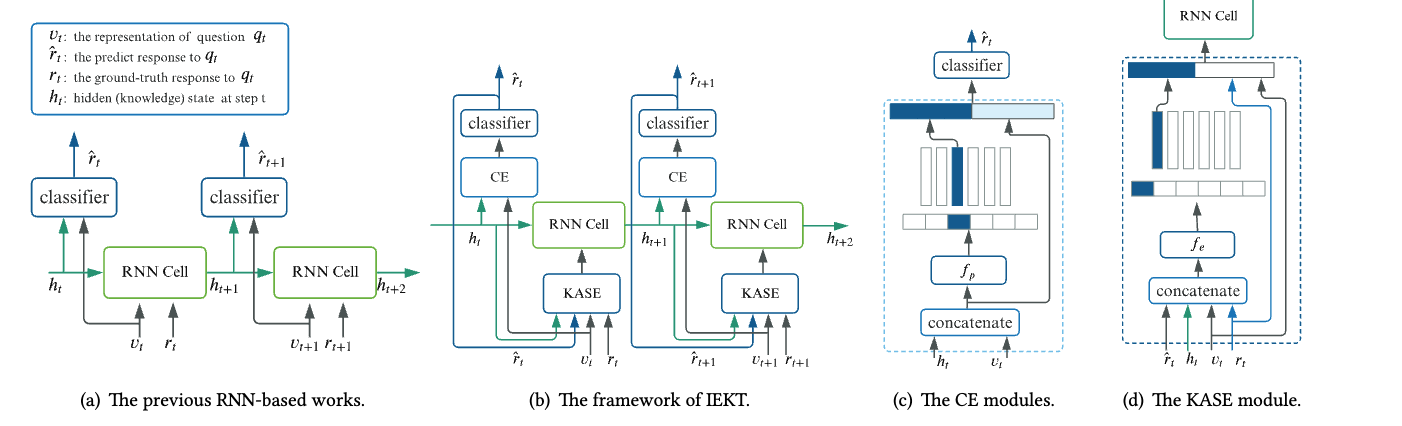
qDKT
qDKT(base) is a model same as DKT, but use the question ID as the input.
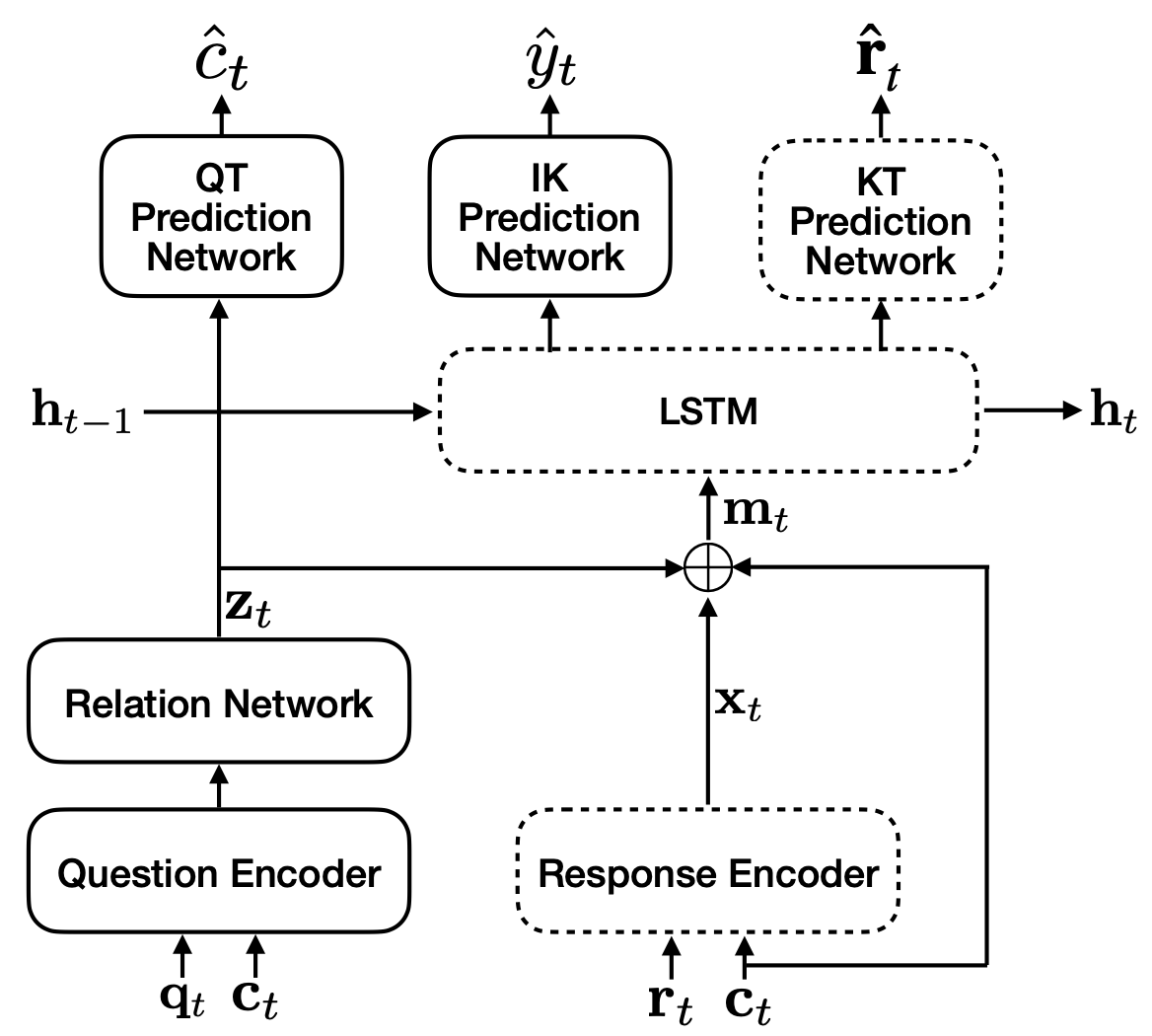
AT-DKT
AT-DKT improve the prediction performance of the original deep knowledge tracing model with two auxiliary learning tasks including question tagging prediction task and individualized prior knowledge prediction task.
simpleKT
simpleKT is a strong but simple baseline method to deal with the KT task by modeling question-specific variations based on Rasch model and use the ordinary dot-product attention function to extract the time-aware information embedded in the student learning interactions.
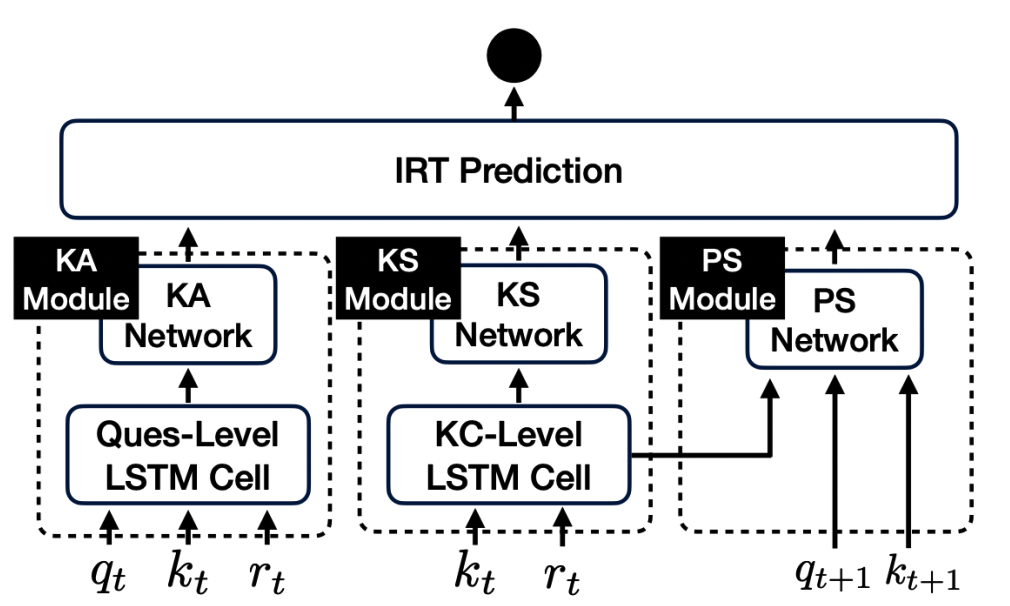
QIKT
QIKT is a question-centric interpretable KT model that estimates students’ knowledge state variations at a fine-grained level with question-sensitive cognitive representations that are jointly learned from a question-centric knowledge acquisition module and a question-centric problem solving module.
sparseKT-soft/topK
sparseKT incorporate a k-selection module to only pick items with the highest attention scores including two sparsification heuristics: (1) soft-thresholding sparse attention (sparseKT-soft) and (2) top-𝐾 sparse attention (sparseKT-topK).
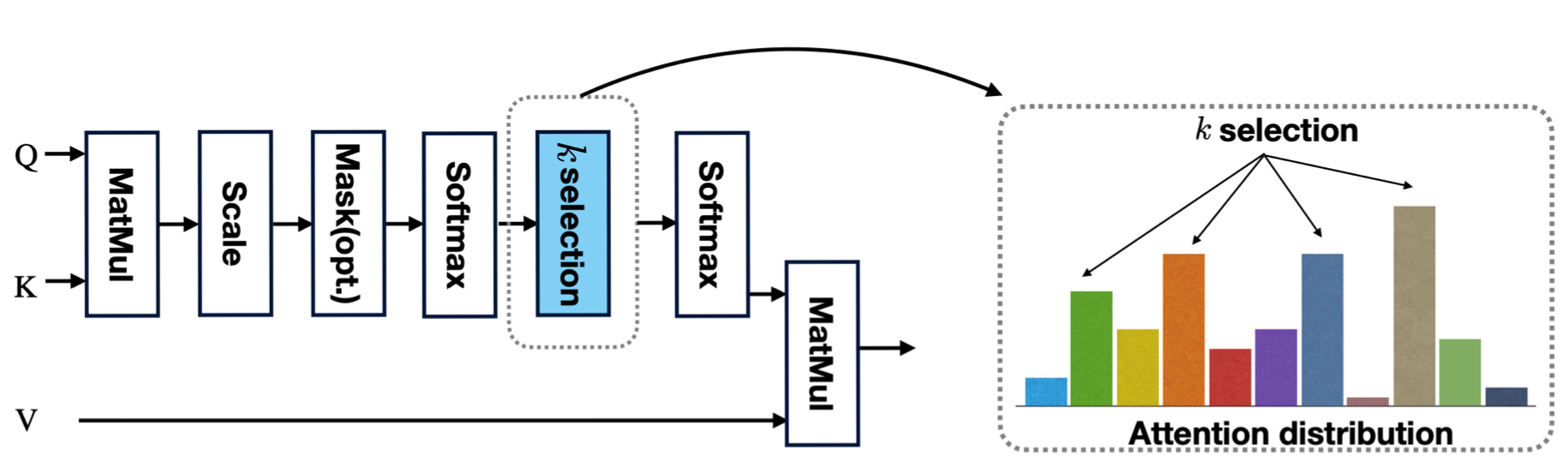
Shuyan Huang, et al. “Towards Robust Knowledge Tracing Models via k-Sparse Attention.” Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2023.
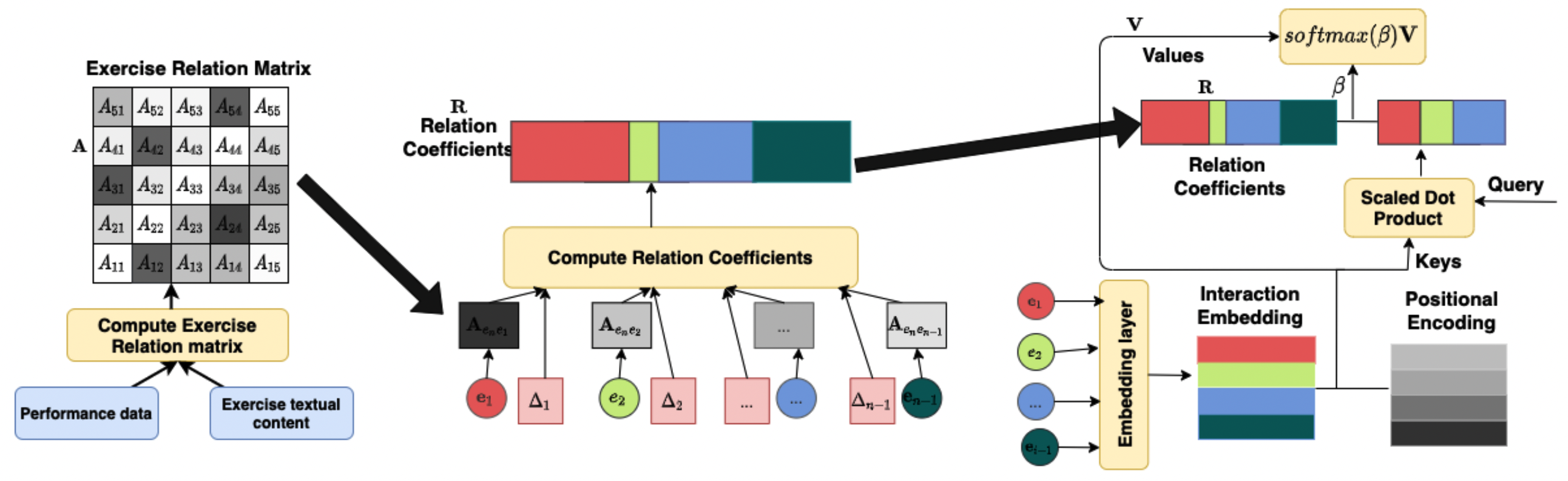
RKT
RKT contains a relation-aware self-attention layer that incorporates the contextual information including both the exercise relation information through their textual content as well as student performance data and the forget behavior information through modeling an exponentially decaying kernel function.
FoLiBiKT
FoLiBi (Forgetting-aware Linear Bias) is a simple yet effective solution that introduces a linear bias term to explicitly model learners’ forgetting behavior, compensating for the neglect of forgetting effects in existing attention-based Knowledge Tracing models。We reproduced FoLiBi with AKT, namely FoLiBiKT.
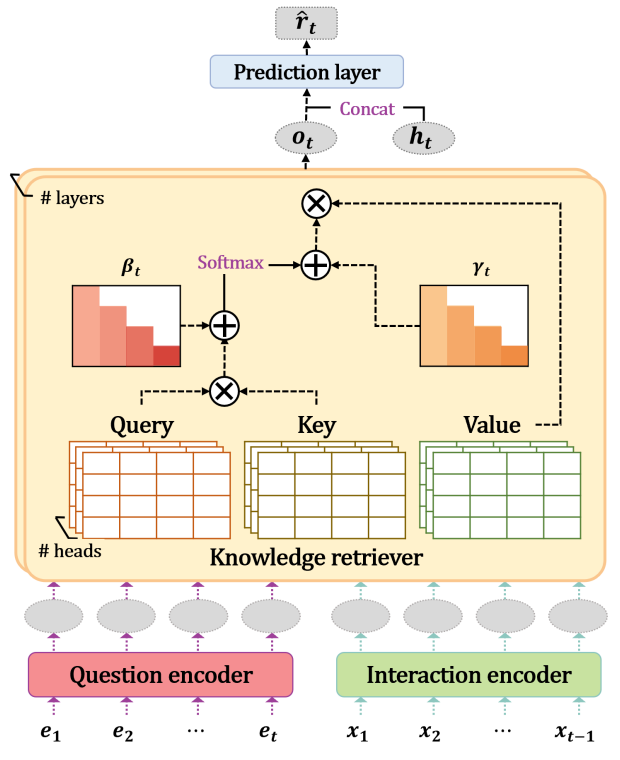
Dtransformer
The Diagnostic Transformer (DTransformer) integrates question-level mastery with knowledge-level diagnosis using Temporal and Cumulative Attention (TCA) and multi-head attention for dynamic knowledge tracing. Moreover, a contrastive learning-based training algorithm enhances the stability of knowledge state diagnosis.